The Genesis of Our AI-Driven Solution
Our journey began with a simple yet ambitious objective: to process news articles from various publishers, extract valuable metadata, and make this information readily accessible to Generative AI. This would allow users to seamless search articles from various sources.
Choosing the Right Framework
After evaluating several options, we chose Spring AI for its seamless integration with Spring applications, intuitive setup, and robust documentation. This decision enabled us to build a foundation that supports various AI components, facilitating a smoother development process.
Architectural Decisions: Data Storage and AI Integration
One of the critical decisions in our project was selecting the appropriate storage solutions. We opted for PostgreSQL to manage the articles and metadata due to our team’s familiarity with relational databases and its proven scalability. For AI-enhanced searching capabilities, we incorporated Neo4j Graph Database, allowing us to later leverage its graph functionalities.
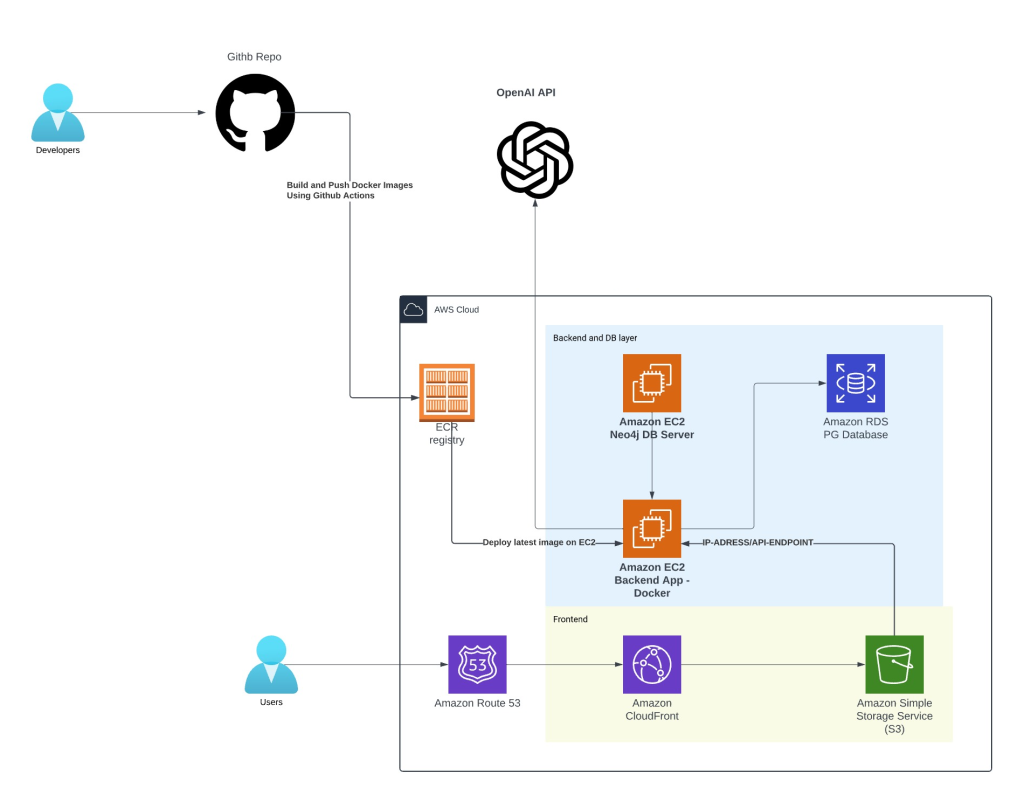
System Architecture and Workflow
Our system architecture is designed to ensure seamless data flow and efficient handling of operations. Here’s an overview of our infrastructure setup:
- Development and Operations: We employ GitHub for source control, where developers commit their code, activating GitHub Actions to build and deploy Docker images to AWS ECR. This seamless integration ensures that our deployment processes are scalable and easily manageable.
- AWS Cloud Infrastructure: Our infrastructure heavily relies on AWS services:
- Amazon EC2: These instances serve as the backbone, hosting our Neo4j and PostgreSQL databases, as well as the backend application.
- Amazon RDS: This service robustly manages the PostgreSQL database, ensuring its high availability and durability.
- Amazon Neo4j: Employed as our vector store, it is pivotal for the AI’s retrieval and generative capabilities.
- Amazon CloudFront and S3: These services manage the delivery of static content and the frontend, ensuring quick and secure access for users globally.
- Route 53: This manages DNS, enhancing our network traffic management and efficiency.
Overcoming Challenges with LLM Integration
Integrating different Language Learning Models (LLMs) posed its own set of challenges, particularly in terms of cost and flexibility. We explored several models, including GPT4All and Ollama locally, and OpenAI’s models for cloud-based solutions. Our findings led us to adopt OpenAI’s GPT-3.5 Turbo for our proof of concept, given its cost-effectiveness and robust performance.
Innovative Solutions: Chunking and Advisor Evolution
The project unveiled the necessity for innovative solutions in handling large text data:
- Chunking: We developed a custom chunking strategy that not only meets the size limitations of embedding models but also ensures that each database node contains the full text of the articles. This approach significantly reduces the complexity of retrieving and reconstructing article content.
- Advisor Interface: Our AI advisor has evolved into a more sophisticated tool that guides the AI in generating responses. This system uses prompt templates and system messages to enhance the relevance and accuracy of the AI’s outputs.

